
Волохин О.М.
Кировоградская ОУНБ им. Д. Чижевского, Украина
Технологическая модель
построения
информационного портала библиотеки
с использованием метаданных Dublin
Core*
Конец 1990-х гг.
можно назвать эрой вступления украинских
библиотек во всемирную паутину WWW. Как грибы
после дождя, в украинском сегменте
Интернета начали появляться сайты
университетских, областных и городских
библиотек.
Возникает
закономерный вопрос о роли и
предназначении этих сайтов во всемирной
сети, которая развивается стихийно. Кроме
того, в украинском и российском Интернете
появилось довольно много так называемых сайтов-библиотек
организаций, сообществ и просто
энтузиастов, которые на самом деле (вне
Интернета) библиотеками как таковыми не
являются.
Достаточно
ли для современной библиотеки опубликовать
пару десятков html-страниц с информацией о
библиотеке, перечнем платных услуг и т.п.?
Что может стать отличительной чертой сайта
профессиональной библиотеки в Интернете? И
как вообще библиотеке оперировать с этой
сетью?
Вопросов
больше, чем ответов. И, к большому сожалению,
приходится констатировать, что украинская
библиотечная наука не изобилует
диссертациями, исследованиями или
практическими разработками на эти темы.
В последнее
время в среде украинских библиотек
поднимается вопрос о создании
информационных порталов. Что должно стать
теоретической, технологической основой
такого портала? На каких стандартах или
форматах он должен базироваться и
развиваться?
Позволю себе предложить результаты
исследований и отдельных разработок
Кировоградской ОУНБ им. Д. Чижевского. (Следует
сказать, что после создания веб-сайта
библиотеки в январе 1999 г. мы и не помышляли о
создании портала. Главным вопросом отдела
автоматизации было определение поля
деятельности научной библиотеки в
Интернете, изучение сферы применения,
технологий и стандартов.)
Структура Интернета
Это огромное
скопление цифровых ресурсов,
распределенное практически по всему
земному шару. Изначально в этой сети не
существует структуры, которая бы
упорядочивала эти ресурсы. Не случайно
оптимисты называют Интернет крупнейшей
кладовой знаний и информации, а пессимисты
– большой мусорной кучей. В подавляющем
большинстве основу этих ресурсов
составляют гипертекстовые файлы,
включающие в себя текст, графику, звук,
видео.
Оценить
Интернет количественно можно только
приблизительно. Это динамическая система,
меняющая свои параметры ежеминутно. Для
того чтобы хоть как-то справляться с таким
объемом неструктурированной информации, в
Интернете существуют поисковые серверы. По
принципу индексирования их можно разделить
на две группы: с автоматическим
индексированием (машинным) и с
интеллектуальным индексированием (с
участием человека).
Первую группу серверов называют поисковыми
машинами или индексирующими
роботами. Они самостоятельно бороздят
просторы Интернета, следуя по ссылкам,
переходят от страницы к странице и заносят
их в свою БД с последующим индексированием
по полному тексту цифрового ресурса. К ним
относятся всемирно известные Google,
Alta Vista, HotBot
и др. Мощнейшие поисковые машины на
просторах СНГ – Рамблер, Апорт, Яндекс,
харьковский сервер МЕТА.
Вторую
группу серверов называют порталами,
каталогами или директориями. Здесь обработку
цифрового ресурса осуществляет человек (каталогизатор),
внося данные в БД портала и индексируя их в
соответствии с различными тезаурусами или
рубрикаторами, т.е. выполняет
интеллектуальную обработку материала.
Наиболее
известным представителем второй группы
является каталог Yahoo!. Приблизительно по этому
принципу построены многие платные
онлайновые БД, вносящие в свои каталоги не
только данные о ресурсах Интернета, но и
материалы газет, журналов, информационных
агентств и пр. Такие БД представляют из себя
уже гибриды каталогов и полнотекстовых
материалов. К ним можно отнести БД Dialog,
Lexis-Nexis, Proquest Direct, EBSCO
и др.
Казалось бы, проблема индексации
информации ресурсов Интернета может быть
решена только поисковыми машинами, ведь
поисковый робот такой машины заносит
полный текст страницы в свою БД и
достаточно того, чтобы робот попал хотя бы
на одну страницу сайта, а далее, следуя по
ссылкам этой страницы, он перейдет к
следующей и следующей и таким образом
постепенно проиндексирует весь сайт.
К сожалению, этого не происходит.
Например, сайт Кировоградской ОУНБ на
протяжении трех лет индексируется
различными поисковыми машинами (не реже
одного раза в месяц). Казалось, трех лет
достаточно для поисковых роботов, чтобы
занести в свою БД все страницы нашего сайта.
Однако проверка наиболее популярных
поисковых машин показала следующее
количество html-страниц Кировоградской ОУНБ
в БД: Google (США) – 680, Rambler
(Россия) – 428, Aport (Россия)
– 1025, Yandex (Россия) –
1570, META (Украина) – 1252.
Отсюда можно
сделать вывод, что поисковые машины не
решают проблему полной индексации всех
ресурсов Интернета, хотя их БД по сравнению
с каталогами (порталами) имеют значительно
больший объем данных и пополняются
несоизмеримо быстрее ввиду автоматической
работы (без участия человека).
Именно поэтому как альтернативный
способ индексации ресурсов сети стали
возникать Интернет-порталы (каталоги,
директории). Чаще всего порталы строятся по
тематическому принципу. Известны, например,
порталы финансовые, СМИ, региональные,
законодательные, литературные и т.д. Их еще
называют вертикальными
порталами. Кроме того, существуют горизонтальные
порталы, т. е. охватывающие несколько тем.
Порталы предназначены дополнять «пробелы»
в определенных отраслях и, если хотите,
исправлять несовершенство поисковых машин,
более подробно освещая конкретные
тематические отрасли интеллектуальным (обработанным
человеком) индексированием ресурсов.
Именно порталы (каталоги) станут предметом
этой статьи.
К вопросу о метаданных
Понятие метаданные,
придуманное информационными специалистами
компьютерных технологий, не является новым
по значению для библиотечного, музейного
или архивного специалиста.
Библиографическая карточка – это не что
иное, как набор метаданных на книгу или
статью из журнала, построенный по правилам
библиографического описания.
Изначально метаданные возникли как
вспомогательная структура для
автоматической индексации цифровых
ресурсов. Иными словами, в код html-страницы, в
области заголовков (между тегами html <HEAD> и </HEAD>)
вносятся в определенном порядке данные,
описывающие определенные параметры. Любая
информация, внесенная в эту область html-документа,
не отображается браузером (компьютерной
программой, предназначенной для показа html-файлов
на экране компьютера, и пользователь может
даже не подозревать, что просматриваемый им
документ несет в себе еще какую-то
дополнительную информацию, однако
программные роботы, да и сам браузер
извлекают эти данные, полезные для решения
определенных задач.
Дальнейшее
развитие сети привело к созданию других
наборов метаданных, предназначенных не
только для оперирования ими роботами, но и
для решения более широкого круга задач.
Сейчас существуют десятки таких
наборов метаданных. Это могут быть
узкоспецифические наборы, предназначенные
для описания ресурсов определенной отрасли
или тематики. Имеются и метаданные более
общего, универсального характера: набор
метаданных VRA4 (Ассоциации визуальных
ресурсов) – для описания цифровых ресурсов,
содержащих графические изображения; набор
метаданных GILS (можно
перевести как Глобальный информационный
указательный сервис), предназначенный для
упрощения поиска и доступа к ресурсам,
предоставляемым в Интернет
государственными и индустриальными
компаниями США; инициатива университета
Беркли EAD (Кодирование архивных описаний),
призванная обеспечить методы описания,
сохранения и доступа к цифровым ресурсам
библиотек, музеев и архивов на основе языка
SGML, и многие другие. Исчерпывающую
информацию (на английском языке) можно
получить на сайте ИФЛА: http://www.ifla.orgIImetadata.htm.
Внимание
Кировоградской ОУНБ привлекла Инициатива
Дублинского Ядра метаданных (Dublin Core Metadata Initiative). Стандарт
метаданных Dublin Core,
или DC – формат описания практически любых
ресурсов Интернета – несложен по структуре,
относительно легок в применении,
расширяемый и интернациональный, т.е.
нашедший свое применение по всему миру.
В конце 1999 г.
принято решение использовать Dublin
Core для собственных цифровых ресурсов на
сайте Кировоградской ОУНБ. Начиная с 2000 г.
введено правило снабжать описанием Dublin
Core практически каждую html-страницу на
сайте библиотеки. Сейчас можно
констатировать, что сайт Кировоградской
ОУНБ является крупнейшим в украинском
сегменте Интернета, где используются
метаданные Dublin Core (около 900 html-страниц).
Возникает
вопрос, правильным ли был выбор среди
множества разнообразных стандартов
метаданных? Думаю, что время – лучший
арбитр в этом вопросе.
Уже сегодня можно констатировать
следующее: в сентябре 2001 г. набор
метаданных Dublin Core
утвержден в США Американским институтом
национальных стандартов как стандарт Z39.85. В
том же году формат Dublin
Core рекомендован и принят как
государственный стандарт для онлайн-ресурсов
и е-коммерции в Австралии, Канаде, Дании,
Финляндии, Ирландии и Великобритании.
Формат Dublin
Core версии 1.1 включает в себя 15 элементов
для описания цифрового ресурса:
Заглавие – Title,
Создатель (Автор)
– Creator,
Тема (Предметная
рубрика) – Subject,
Описание (Аннотация)
– Description,
Издатель – Publisher,
Соавтор –Contributor,
Дата – Date,
Формат – Format,
Тип – Type,
Идентификатор
– Identifier,
Источник – Source,
Язык – Language,
Отношение – Relation,
Охват (Покрытие)
– Coverage,
Авторские
права – Rights.
По правилам Dublin
Core каждый из 15 элементов не является
обязательным и может повторяться. В самом
общем случае для внесения любого элемента
достаточно пары – имя
и значение (Content):
<meta name="DC.ИМЯ" content="ЗНАЧЕНИЕ">
Рассмотрим
реальный пример для элемента «Создатель
(Автор)",
закодированный в языке HTML
версии 4.0: <meta name="DC.
Creator" content="Энгельс,
Фридрих">
Для более
детального описания некоторых элементов
применяются подэлементы, называемые квалификаторами.
К квалификаторам относятся дополнительные
подтипы основного элемента и схемы.
Например, можно уточнить тип автора (коллективный
или индивидуальный) с помощью
квалификатора: <meta name="DC. Creator. PersonalName"
content="Маркс,
Карл">.
С помощью квалификатора схема
(Scheme) можно пояснить,
из какого контролируемого словаря взято
значение элемента: <meta name="DC.
Subject" scheme="
ББК" content=" Другие разделы
спектроскопии">
<meta name="DC.Subject" scheme="ББК" content="B344.9">
Применение квалификаторов
желательно, но не обязательно, все зависит
от того, насколько детально вы желаете
составить описание цифрового ресурса.
Порядок следования элементов не имеет
значения.
Полное
описание по использованию Dublin
Core не входит в задачи данной статьи. С
форматом Dublin Core
можно ознакомиться на украинском языке на
сайте библиотеки им. Л. Украинки, на русском
– на сайте Российской государственной
библиотеки.
Практическое
использование Dublin Core
в библиотеке
Для более
легкого понимания вопросов использования
метаданных Dublin Core
уместно провести ряд параллелей и допусков.
Посмотрим на описание ресурсов Интернета
как на традиционную библиотечную работу по
составлению каталога:
-
Описание с
использованием Dublin Core
ресурсов Интернета есть не что иное, как
библиографическое описание книги или
аналитической статьи журнала (газеты).
-
Поскольку
правила библиографического описания (ГОСТ 7.1–84) не касаются цифровых ресурсов,
будем считать, что правила Dublin
Core и есть наш свод правил по описанию этих
ресурсов (кстати, с учетом последнего
мирового опыта), т.е. Dublin
Core – это «ГОСТ 7.1–84» для Интернета.
-
Традиционный каталог предусматривает
хранение библиографической карточки
отдельно от первоисточника (для бумажного
каталога – карточка в каталожном ящике, для
электронного – запись в библиографической
БД). Мы будем придерживаться всего того, что
касается электронного каталога. Но
дополнительно учтем, что пользователь
Интернета находится вне стен библиотеки и
не сможет получить доступ к карточному
каталогу. Поэтому, создавая описание Dublin
Core для html-страниц собственного сервера,
мы помещаем это описание в коде HTML непосредственно в тело
публикуемого документа. Иными словами, мы
публикуем в Интернете электронный документ
и одновременно «вшиваем» каталожную
карточку в тело первоисточника.
Теперь возникает закономерный вопрос:
как сделать доступным для пользователя
просмотр такой электронной карточки, а для
каталогизатора – работу с ней? Ведь не
каждый пользователь знает, как отыскать и
выделить в коде html-страницы эту полезную
информацию.
Признаюсь, в
глазах моих коллег по отделу, создававших
описания в стандарте Dublin Core на протяжении последних двух
лет, я видел немой упрек – зачем вносить
метаданные Dublin Core в
html-страницы, если от них нет никакого
практического толка?
Действительно,
эти данные никак не отобразятся в экране
браузера и пользователь, просматривающий
страницу, даже и не подозревает, что эта
страница имеет в себе вторичные данные,
позволяющие получить ее краткое описание.
Кроме того, сегодня ни одна известная
поисковая машина Интернета не использует Dublin
Core для индексации ресурса, она их просто
игнорирует. Логичным будет предположить,
что для реального использования Dublin Core необходимы какие-то
дополнительные онлайновые программы-утилиты,
позволяющие решить эту проблему. О таких
программах, созданных в Кировоградской
ОУНБ, пойдет речь далее.
Утилита «Просмотрщик-конвертор
метаданных Dublin Core»
С осени 2001 г. на html-страницах
сайта Кировоградской ОУНБ начали
появляться линки DC. Metadata. Расположены они в верхнем
левом углу страницы. При нажатии курсором
на такой линк заработает программа на языке
Perl, сформирует и
покажет html-страницу с метаданными Dublin
Core в удобном для чтения виде. Иными
словами, программа выберет из html-кода
страницы полезные описательные данные и
покажет фактически электронную каталожную
карточку о Интернет-документе, который вы
собираетесь читать.
Согласитесь,
если вы собираетесь просматривать ресурс
размером в несколько печатных страниц, а
может быть, и десятков страниц – такие
описательные данные вряд ли будут лишними.
Кстати, если
вы используете Dublin Core
на своем сайте, то можете воспользоваться
преимуществами онлайновых технологий. Для
этого в коде ваших html-страниц разместите
следующую строку:
<a href="http://www.library.kr.uacgi-bin/dcview.cgi">DC.Metadata </a>.
Этого достаточно для того, чтобы на
странице вашего сервера появился линк DC.
Metadata, и пользователи вашего сервера
смогут просматривать описательные данные Dublin Core вашей страницы.
Следующая программа является
продолжением предыдущей, но с расширенными
функциями (http://www.library.kr.ua/dc/lookatdc.html). Ее предназначение – возможность
тестировать любые страницы Интернета на
предмет наличия метаданных Dublin
Core. Это поисковая программа с интерфейсом
на трех языках (украинском, русском и
английском). Кроме того, вы можете получать
вторичную информацию о страницах даже в том
случае, если они не имеют метаданных Dublin Core. Программа просто сгенерирует
максимально возможное количество данных из
других, сопутствующих параметров и ответов
сервера, а далее перекодирует их на лету в
формат Dublin Core.
Косвенно
программа позволяет судить вообще о
присутствии метаданных на странице, так как
использует в своей работе стандартные html-метаданные,
предназначенные для опознавания страницы
традиционными поисковыми машинами
Интернета.
Я провел
небольшое тестирование веб-ресурсов
некоторых библиотек Украины и ведущих
библиотек России на предмет наличия
метаданных. Результаты оказались
плачевными. Можно утверждать, что
библиотеки не уделяют этому вопросу
должного внимания.
Утилита «Редактор-конвертор
метаданных Dublin Core»
(версия
1.1)
Эту
программу можно отыскать по адресу: http://www.library.kr.ua/dc/dcedituni.html.
Ее можно использовать в двух направлениях:
как полнофункциональный редактор
метаданных Dublin Core для создания, редактирования и
последующего внесения созданного кода в
реальную html-страницу (в формате языка HTML 4.0); как конвертор из формата
метаданных Dublin Core в библиографический формат
обмена данными UNIMARC (RUSMARC, UKRMARC) с
последующим сохранением данных в файле ISO–2709.
Кроме
того, при помощи этой программы
представляется возможным построить
технологию создания и развития
информационного портала библиотеки в
Интернете, максимально приблизив эту
работу к традиционным библиотечным
функциям – созданию библиотечного
каталога (вторичной информации о ресурсах).
Таким образом, библиотека фактически будет
работать в обычной среде применительно к
новым ресурсам, расположенным в Интернете.
Использование Редактора-конвертора можно
представить на следующей блок-схеме:
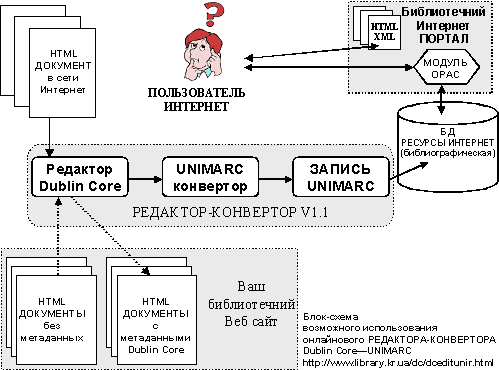
Использование Редактора-конвертора
в качестве редактора Dublin
Core
Такой этап
работы с Редактором-конвертором версии 1.1. (РК
v1.1) можно считать
промежуточным. Он предназначен для
создания и редактирования метаданных DC уже существующих html-страниц. В
случае, если html-страница
еще не имеет метаданных, DC–PKv1.1
сгенерирует их, используя попутные
метаданные и ответы сервера.
Интерфейс PKv1.1
в стадии редактирования состоит из двух зон:
окна метаданных, закодированных по
правилам языка HTML 4.0,
и собственно редактора с полями ввода
данных (нижний экран).
Там, где это
возможно в соответствии с правилами
стандарта DC,
редактор снабжен выпадающими меню с
вариантами заполнения поля конкретного
элемента. Имеется краткая система помощи по
каждому элементу DC с
рекомендациями по использованию и
несколькими примерами. Такая помощь
появляется в отдельном окне браузера. Чтобы
исключить проблемы с отображением
кодировок, редактор автоматически
перекодирует ответы сервера из кодировки KOI-8R
в кодировку Windows-1251.
Имеется возможность добавления строк для
каждого элемента соответствующей кнопкой + имя
элемента, если все поля данного элемента
уже заполнены.
После
внесения данных или их коррекции в каком-либо
поле необходимо использовать кнопку DC-Изменить
для учета проведенных изменений; затем
редактор отобразит в верхнем экране ваши
изменения в коде HTML (синим
цветом). Если вы считаете редактирование
метаданных законченным, достаточно
выделить мышкой код, изображенный синим
цветом, скопировать его в буфер обмена (Ctrl+C) и при помощи любого текстового
редактора вставить данные в реальную html-страницу
между тегами <HEAD>
и </HEAD>.
Использование Редактора-конвертора в
качестве конвертора
Dublin Core – UNIMARC
Этот этап
используется в том случае, когда необходимо
сохранить метаданные о html-странице в
библиографической БД в формате UNIMARC
(RUSMARC, UKRMARC). По окончании создания или
редактирования метаданных DC необходимо
использовать кнопку редактора UNIMARC.
Программа произведет конвертирование и
покажет вам новый экран в формате UNIMARC.
Теоретические вопросы конверсии из Dublin
Core в UNIMARC
Основная
проблема конверсии заключается в том, что
формат Dublin Core
является более простым по сравнению с UNIMARC. Для формата UNIMARC
– профессионального формата передачи данных,
который учитывает правила
библиографического описания, –
обязательна более строгая детализация
отдельных элементов описания. Для
наглядности приведу таблицу мапирования –
таблицу соответствий между элементами двух
форматов, которые использует программа
(некоторые детали исключены для улучшения
читаемости).
|
Dublin Core
|
UNIMARC
|
|
Title
(Заглавие)
|
200 $a Основное
заглавие
|
|
|
200 $e Сведения, относящиеся к заглавию
|
|
|
517 $a Вариант заглавия
|
|
Creator
(Создатель, Автор)
|
700 $a Имя лица – первичная
интеллектуальная ответственность
701 $a
Имя лица – альтернативная
интеллектуальная ответственность
710 $a
Наименование организации – первичная
интеллектуальная ответственность
711 $a
Наименование организации –
альтернативная интеллектуальная
ответственность
200 $f
Первые сведения об ответственности
|
|
Subject
(Предмет. Ключевые слова)
|
610 $a Неконтролируемые предметные
термины
606
Наименование темы как предмет
675
Универсальная десятичная классификация
(UDC/УДК)
676
Десятичная классификация Дьюи (DDC/ДДК)
680
Классификация Библиотеки Конгресса (LCC/КБК)
686
Индексы других классификаций
|
|
Description
(Описание)
|
330 $а Резюме или реферат
|
|
Publisher
(Издатель)
|
210 $c Имя издателя, распространителя и т.д.
|
|
Contributor
(Соавтор)
|
701 $а Имя лица – альтернативная
интеллектуальная ответственность
711 $a
Наименование организации –
альтернативная интеллектуальная
ответственность
200 $g
Последующие сведения об
ответственности
|
|
Date
(Дата)
|
210 $d Дата издания, распространения и т.д.
|
|
Type
(Тип)
|
608 Форма, жанр, физическая
характеристика документа как точка
доступа
|
|
Format
(Формат)
|
230 $a Специфическая область материала:
характеристика электронного ресурса
336 $a
Тип компьютерного файла
|
|
Identifier
(Идентификатор)
|
001 (обязательное для UNIMARC)
010 (ISBN)
011 (ISSN)
020 (Номер
документа в национальной библиографии)
035
Другие системные номера
856 $u (URL)
|
|
Source
(Источник)
|
324 Оригинальная версия примечания
|
|
Language
(Язык)
|
101 Язык документа
|
|
Reletion
(Отношение)
|
300 Общие примечания
|
|
Covarage
(Охват. Покрытие)
|
300 Общие примечания
|
|
Rights
(Авторские права)
|
333 Примечания об
особенностях распространения и
использования
|
Для
формата UNIMARC (UKRMARC, RUSMARC)
некоторые поля обязательны, без их наличия
запись не будет полноценной. Приведу
таблицу этих обязательных полей и
соответствующие им поля формата Dublin
Core:
|
UNIMARC
|
Dublin Core
|
|
001 – Идентификатор записи
|
Identificator
(Идентификатор)
|
|
100 – Данные общей обработки
|
Date
(Дата),
Language (Язык)
|
|
101 – Язык документа
|
Language
(Язык)
|
200 – Заглавие и сведения
об ответственности
|
Title
(Заглавие), Creator (Создатель,
Автор), Contributor (Соавтор)
|
Однако
согласно правилам Dublin
Core любой из 15 элементов не является
обязательным. Иными словами, описание
ресурса в формате Dublin
Core, где отсутствуют перечисленные выше
элементы будет вполне корректным. Поэтому в
случае отсутствия в описании элементов Identificator
(Идентификатор) и Date (Дата)
PKv1.1 создаст их
самостоятельно на основе ответов сервера.
При отсутствии элементов Title
(Заглавие) и Language (Язык)
– РКv1.1 не будет
конвертировать описание в формате UNIMARC
до тех пор, пока каталогизатор не внесет
заглавие элемента в поле Title и код языка (языков) вручную.
Вполне
возможен вариант, когда в описании
отсутствуют элементы «Автор» и/или «Соавтор»,
конвертирование в этом случае будет
произведено, но при наличии данных в этих
полях PKv1.1
обязательно потребует указать вручную тип
автора (коллективный или персональный).
Конечно,
можно и не конвертировать данные в формате UNIMARC,
не заносить их в библиографическую БД, а
остановиться на промежуточном этапе –
сохранять данные в формате Dublin
Core и на их основе строить портал
библиотеки в Интернете. Однако, на мой
взгляд, это не совсем логично для
библиотеки. Во-первых, потребуется какая-то
дополнительная среда для хранения данных.
Во-вторых, необходимо создание механизма
доступа, поиска и извлечения данных из
такой БД. И в-третьих, этот массив данных
будет оторван от остальных информационных
массивов библиотеки.
И последний
вопрос. А стоит ли библиотеке создавать
информационный портал? Ресурсов в
Интернете так много, а библиотекарей в
вашей библиотеке так мало. Ресурсы
мигрируют в сети: появляются, исчезают,
меняют место прописки… Как за всем этим
угнаться???
Первое, что
необходимо помнить – предназначение
портала. Этот вид поискового сервиса в
Интернете не может охватить все. Поэтому
необходимо ориентироваться на конкретную
тему или ряд тем, которые может охватить ваш
портал. Наверное, прежде всего он должен
быть литературным, а во вторую очередь –
региональным.
Менее
успешным будет проект, в котором вы
попытаетесь охватить все. Скорее всего из
этого получится «обо всем – практически ни
о чем» и для будущего пользователя вашего
портала будет иметь соответствующую цену.
Во все века
библиотека специализировалась (в
информационном смысле) на создании
вторичной информации о документах, т.е.
каталогов. Это, конечно же, не значит, что
библиотека должна отказаться от
издательской деятельности. Наоборот, при
помощи Интернета стало гораздо проще
публиковать полнотекстовые материалы. Но
уже сегодня можно констатировать, что в
публикациях полных текстов книг в
русскоязычном и украиноязычном сегменте
Интернета профессиональные библиотеки
безнадежно утратили свои позиции.
За последние
5–6 лет в Интернете появилось огромное
количество полнотекстовых библиотек,
созданных энтузиастами от литературы.
Количество полнотекстовых книг составляет
десятки тысяч!!! Кто-то скажет: не
библиотечное это дело заниматься
публикациями в таких объемах – и, наверное,
будет прав. Возможно, более логичным будет
публикация в Интернете редких книг из
собственных коллекций – без нарушения при
этом закона об авторских правах. И тем не
менее не лишним будет создание адресных
каталогов библиотек Мошкова, Пескина и
подобных украинских сайтов.
Заключение.
В качестве базового стандарта для
взаимодействия с Интернетом
Кировоградская ОУНБ предлагает
использовать формат метаданных Dublin
Core, для изучения которого со стороны
библиотек потребуются определенные усилия,
но в остальном эта технология и
разработанное программное обеспечение
вписываются в рамки традиционной
библиотечной работы. В будущем библиотека
планирует расширить возможности Редактора-конвертора
путем создания дополнительных конверторов
метаданных из формата Dublin Core в XML-формат
и другие.
*
Доклад публикуется с сокращениями.
|