Бродовский А.И., Попов Е.В., Сбойчаков К.О.
ГПНТБ России
ИРБИС64 как инструмент создания и ведения полнотекстовых баз данных
Результаты работы по созданию оригинальной версии ИРБИС64, предназначенной для работы с полнотекстовыми БД. |
Подробное описание алгоритмов ранжированного поиска и поиска "схожих" документов.
В предыдущих работах [1, 2] в качестве основной задачи развития системы автоматизации библиотек ИРБИС64 определена поддержка полнотекстовых БД с обеспечением классификации и смыслового анализа текстов. В настоящее время в ГПНТБ России в рамках ИРБИС64 создана подсистема (далее система) для формирования и использования полнотекстовых БД. Тексты, составляющие такие БД, могут быть в форматах TXT, DOC, RTF, PDF, HTML. Никакой дополнительной обработки для включения полных текстов в БД не требуется, они сохраняются в БД в специальном архивном файле или в виде ссылок.
Основой данной разработки служит уже неоднократно представленная на международных конференциях "Крым" и "Либком" система смыслового анализа текстов [3, 4]. Подходы к решению задачи смысловой обработки текстов, применяемые в системе, могут быть вкратце сформулированы в виде следующих этапов:
1. Создание полнотекстовой БД из массива текстов.
2. Естественно-тематическая классификация текстов на основе выделения значимых терминов предметной области. Тематическая классификация позволяет сравнивать тексты между собой на предмет близости их по смыслу. Тематический классификатор - это набор тематических словарей, в который входят термины, значимые в данной предметной области.
Система полнотекстовых баз данных ИРБИС64 включает:
1. Расширенный АРМ "Администратор", который помимо стандартных для ИРБИС функций администрирования содержит дополнительные режимы для работы с полнотекстовыми БД.
2. АРМ конечного пользователя (читателя) для поиска и просмотра полнотекстовых БД в локальной сети или на CD-ROM. В этом АРМе реализованы специальные поисковые алгоритмы: поиск по запросу на естественном языке с ранжированием найденных текстов; поиск "схожих" текстов в заданном пользователем тематическом контексте; кроме того, АРМ позволяет публиковать (представлять) Интернет-сайты, описывающие полнотекстовые БД в целом.
3. Шлюз для доступа к полнотекстовым БД по технологии WWW.
Остановимся подробнее на алгоритмах ранжированного поиска и поиска "схожих" текстов, представляющих собой оригинальные решения.
Алгоритм ранжированного поиска
В системе применяется алгоритм поиска с ранжированием, близкий к классическому алгоритму TF*IDF [5, 6], который расширен за счет учета расстояний между словами, увеличения весов терминов, входящих в тематические словари.
При разборе строки запроса на естественном языке производится предварительная фильтрация с целью удаления стоп-слов, специальных символов и слишком коротких слов (менее двух символов). Далее слова подвергаются усечению (выделению основ), отбрасываются слова, не имеющие ссылок в словаре базы данных, и формируется окончательный список слов запроса, соединенных логикой "И".
Вес каждого слова в запросе оценивается следующим образом:
где TF - частотность слова в тексте (в системе этот параметр равен 1),
IDF - коэффициент уменьшения веса слова в зависимости от его распространенности в словаре базы данных.
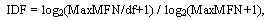
где MaxMFN - число текстов в БД, df - число текстов, содержащих данное слово.
Если слово находится в словаре тематического классификатора системы, заданного в качестве контекста поиска (если контекст поиска не задан пользователем, по умолчанию используется общий контекст БД), то вес его умножается на эвристический коэффициент (1000).
При расчете ранга текста RANG используется вес слов запроса TFIDF и расстояния между ними в тексте. Причем для каждой пары слов берется минимальное расстояние между ними.
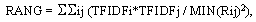
где Rij - расстояние между парой слов. Если слова рядом, Rij = 1.
Вводится следующее различие в работе алгоритма в зависимости от длины запроса:
При поиске можно указать дополнительный параметр - максимальное расстояние между словами. В этом случае необходимым условием выдачи является наличие в тексте фрагментов, включающих все найденные слова из запроса. Если результат поиска нулевой, делается попытка применить менее строгий критерий отбора за счет учета неполных фрагментов. При расчете ранга текста используется минимальное расстояние между словами (см. выше), т. е. постулируется принцип - лучше один "хороший" фрагмент, чем несколько "плохих".
Максимальный размер фрагмента (для включения текста в выдачу) составляет величину:
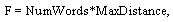
где NumWords - число слов в запросе, MaxDistance - максимальное расстояние между словами.
Алгоритм поиска "схожих" текстов
В расширенном АРМе "Администратор" предлагается ориентированная на пользователя-эксперта автоматизированная технология создания тематических словарей (контекстов), составляющих основу естественно-тематической классификации [4]. Причем основной тематический словарь БД, составляющий ее основной тематический контекст и включающий наиболее общую терминологию, создается автоматически.
Алгоритм поиска "схожих" текстов базируется на использовании естественно-тематической классификации. При этом сначала производится пересечение заданного контекста поиска (тематических словарей) и текста, выбранного в качестве образца. В результате формируется список слов, общих для контекста и текста-образца. Объем этого списка относительно контекста ограничивается снизу параметром настройки "Степень сходства", который принимает следующие значения:
>= 5 % - слабо
>=10% и <15% - приблизительно
>=15% - точно.
Слова из этого списка составляют поисковый запрос. В этом случае ранжирование результатов поиска производится без учета расстояний между словами, играет роль только вес слова TFIDF. Скорость работы алгоритма значительно оптимизирована за счет кэширования ссылок терминов контекста.
Примером практического применения представленной системы служит CD-ROM с полнотекстовой БД материалов Конференции "Крым-2005", который получили все участники этого форума.
Список литературы
1. Бродовский А.И., Сбойчаков К.О. Новое поколение системы автоматизации библиотек ИРБИС - ИРБИС64: от электронного каталога к полнотекстовым базам данных // Библиотеки и ассоциации в меняющемся мире: новые технологии и новые формы сотрудничества: Тр конф. - М., 2004.
2. Бродовский А.И., Сбойчаков К.О. Полнотекстовые базы данных в системе ИРБИС64 // Информационные технологии, компьютерные системы и издательская продукция для библиотек: Тр. конф. - М., 2004.
3. Макагонов П.П., Сбойчаков К.О. Интерактивные методы решения слабо-формализованных задач в гуманитарных и естественнонаучных приложениях: (Визуальный эвристический кластерный анализ) // Материалы симпозиума по компьютерным приложениям CIC'98. Мексик. нац. политехн. ин-т. - Мехико, 1998. - C. 346-358. - Aнгл. яз.
4. Макагонов П.П., Александров М.А., Сбойчаков К.О. Программное обеспечение для создания предметно-ориентированных словарей и кластеризации текстов в полнотекстовых базах данных // Компьютерная лингвистика и интеллектуальная обработка текстов. - Б. м.: Шпрингер, 2001. - C. 454-456. - Aнгл. яз.
5. Сallan J.P., Croft W.B. and Harding S.M. The INQUERY Retrieval System // A. M. Tjoa and I. Ramos (eds.), Database and Expert System Applications. Proceedings of {DEXA}-92, 3-rd International Conference on Database and Expert Systems Applications. - Springer Verlag, New York. - 1992. - Р. 78-93.
6. Агеев М.С., Добров Б.В., Лукашевич Н.В., Сидоров А.В. Экспериментальные алгоритмы поиска/классификации и сравнение с "basic line" // РОМИП'2004: Тр. конф. - М., 2004.
7. Сегалович И., Маслов М. Яндекс на РОМИП'2004. Некоторые аспекты полнотекстового поиска и ранжирования в Яндекс // РОМИП'2004: Тр. конф. - М., 2004.