Научные и технические библиотеки
Антопольский А.Б.
НТЦ «Информрегистр»,
Москва
Системы метаданных в электронных библиотеках
Введение
Система метаданных является центральным логическим компонентом любой электронной библиотеки (ЭБ). Подобно тому, как библиотечный каталог организует все множество единиц хранения в систему библиотечных фондов, вокруг которой строятся все библиотечные технологии, система метаданных организует совокупность электронных информационных ресурсов (или цифровых объектов) ЭБ.
Соответственно вокруг системы метаданных и на ее основе строятся основные технологические процессы ЭБ:
-
навигация в информационном пространстве ЭБ;
-
поиск отдельных цифровых объектов (информационных ресурсов) или их совокупностей;
-
ввод, обработка и организация хранения цифровых объектов, а также их исключение (изъятие);
-
управление правами доступа к цифровым объектам, включая защиту авторских прав, организацию платы за доступ и пр.
Поскольку современные ЭБ реализуются, как правило, в сетевом режиме, система метаданных должна быть согласована с требованиями сетевой архитектуры ЭБ, например архитектуры «клиент-сервер», и протоколами сетевого доступа. Таким образом, система метаданных является связующим звеном между внутренними свойствами ЭБ, обусловленными семантикой и структурой цифровых объектов и функциональными пользовательскими задачами, и внешними свойствами, обусловленными сетевой средой. При этом различные категории пользователей предъявляют к системе метаданных различные, обычно противоречивые требования. Пользователями метаданных являются все категории пользователей ЭБ – как внешние, так и персонал ЭБ, включая лиц, ответственных за управление правами. Однако основным «пользователем» метаданных являются программные средства, реализованные в ЭБ, поэтому формализация метаданных является их обязательным условием.
Еще одним общим свойством метаданных является их относительный характер: сведения, которые в одной информационной системе – метаданные, в другой – собственно данные. Наиболее характерный пример – библиографические или реферативные базы данных, которые в информационных системах прежних поколений были метаданными к традиционным (бумажным) ресурсам (иногда называвшимся вторым контуром информационных систем). В то же время в рамках собственно автоматизированного контура АИС эти БД содержали именно данные.
Относительный характер метаданных выражается также в том, что многие метаданные являются одновременно данными, поскольку присутствуют как в метаописании цифрового объекта, так и в самом объекте. Таковы, например, заглавие, автор, аннотация и другие характерные метаданные обычных текстовых документов. Для других видов цифровых объектов, например изображений, представленных в виде графических файлов, никакие метаданные в состав объекта не входят.
Если понятие метаданные рассматривать в аспекте истории информатики, то это понятие является интегральным по отношению к таким традиционным понятиям, принятым в 1970–1980-х гг., как форматы представления данных, языки описания данных, лингвистическое обеспечение АИС. Главное отличие понятия метаданные от перечисленных понятий заключается в более общем характере метаданных, подобно тому как цифровой объект (информационный ресурс) является более широким понятием по сравнению с понятиями документ или единица хранения предыдущих поколений информационных систем.
Следует еще раз подчеркнуть главную, на мой взгляд, отличительную черту современного этапа развития информатики. Интернет стал общей площадкой, где столкнулись различные и до того развивавшиеся почти независимо информационные субкультуры, например такие, как библиотечное дело или электронная коммерция. При этом системы метаданных стали эпицентром этого взаимодействия, именно той точкой, где поиск единого языка (или, как принято сейчас выражаться, интероперабельности) является наиболее актуальным.
Основные типы метаданных
Большинство исследователей выделяет следующие типы метаданных:
-
описательные, например библиографическая информация или другие сведения о содержании (семантике) цифровых объектов;
-
структурные, включая сведения о форматах, структуре, объеме и других формальных свойствах цифровых объектов;
-
административные – права, разрешения на доступ, на коррекцию данных, данные о пользователе, данные для систем оплаты, технологические данные.
Особым типом метаданных является идентификатор, задача которого – однозначное представление цифрового объекта для внешнего мира и различных приложений.
Необходимо сразу оговориться, что проблема идентификации цифровых объектов является одной из самых сложных в теории и практике ЭБ. Доказательством этому может служить 4-уровневая модель произведения, предложенная ИФЛА, вокруг которой не утихают споры. Аналогичные дискуссии ведутся и по поводу стандарта на код цифровых текстовых документов (ISTC), который в настоящее время разрабатывается в рамках ИСО. Тем не менее любая система метаданных обязательно включает идентификатор, используемый, по крайней мере, в рамках конкретной ЭБ и в пределах принятой в данной ЭБ методологии идентификации.
Вопрос о соотношении типов метаданных в рамках конкретной системы метаданных является принципиальным для выбора системы. Ниже рассмотрены наиболее известные системы метаданных, среди которых наиболее распространенной является система метаданных так называемого Дублинского ядра (Dublin Core Metadata Set). Основная тема дискуссий вокруг возможного внедрения Дублинского ядра как универсальной системы метаданных – спор о возможности и целесообразности решать задачи управления правами на основе этой системы по сравнению со специализированными системами метаданных, предназначенными для этой цели, как например система метаданных INDECS.
Иначе говоря, вопрос старый, как мир: что лучше, универсальная или специализированная система? И ответ на него давно известен: смотря для чего. Выбор системы метаданных и класс задач, решаемых на основе этой системы, определяется функциональностью ЭБ, для которой эта система метаданных создается. Что же касается Дублинского ядра, то областью применения этой системы метаданных по замыслу должен стать весь Интернет. Очевидно, что при такой сверхуниверсальной области применения система метаданных должна обладать максимальной простотой.
Что же касается структурных и административных метаданных, то они известны давно и широко использовались в развитых корпоративных системах для задач управления данными. Специальные системы метаданных этого типа известны под названием системы словарей-справочников. В последние годы, особенно в Интернете, эти системы стали интегрироваться в единые системы с описательными метаданными.
Основные системы метаданных
Перечень некоторых наиболее известных систем метаданных:
DC – Дублинское ядро метаданных – консорциум W3 (подробнее см. ниже).
CSDGM – стандарт для цифровых геопространственных данных. Документ направлен на выработку общей терминологии геопространственных метаданных. Одобрен в 1994 г. на заседании Федерального комитета по географическим данным США и затем утвержден Правительственным распоряжением 12096, которое обязывает американские федеральные организации использовать этот стандарт начиная с 1995 г. Федеральный комитет развивал этот стандарт, чтобы помогать идентифицировать источники пространственных данных и обеспечивать доступ к данным через Национальную информационную инфраструктуру. Стандарт метаданных GSDGM содержит 334 элемента данных, более 100 из которых служат для описания связей между элементами.
DIF – формат обмена для справочников геопространственных данных. Структура данных для каталога метаданных, создаваемая NASA и поддерживаемая в США межведомственной рабочей группой по управлению данными для глобального обмена. Формат разработан в конце 1980-х гг. для обмена спутниковой и другой телеметрической информацией. Позже стал использоваться для любых геопространственных данных и стал стандартом де-факто в международных глобальных информационных системах. Стандарт вводит элементы метаданных, определяет их содержание и структуру для передачи метаданных в информационных системах; позволяет пользователю определить, содержит ли набор данных релевантную информацию.
GILS – Глобальная (правительственная) служба поиска информации. Являясь частью Национальной информационной инфраструктуры, GILS обеспечивает доступ частным лицам и организациям к федеральным информационным ресурсам через общедоступный каталог этих ресурсов. GILS базируется на международных стандартах информационного поиска с применением протокола доступа Z39.50 и использует систему метаданных в рамках этого протокола. Развитие системы GILS предполагает создание системы взаимосвязанных каталогов для поиска метаданных, возможно, различных типов.
MARC – машиночитаемый каталог. Один из старейших и самых известных и распространенных в России и в мире стандартов метаданных. Отличается детальным составом элементов данных, универсальностью, развитой структурой. Ориентирован на библиотечную практику, имеет конкурирующие версии и высокую стоимость эксплуатации.
ЕАД – кодировка архивных описаний. Набор изначально текстовых метаданных на базе языка разметки SGML, разработанных для нужд архивов и используемых для стандартизации и классификации уникальных архивных материалов, прежде всего рукописей. Версия 1.0 1998 г. совместима с форматом XML. Поддерживается Американским архивным обществом и Библиотекой Конгресса США.
TEI – инициатива по кодированию текстов http://www-tei.uic.edu/orgs/tei/; разработана в Центре электронных текстов Вирджинии в 1989 г. как инструмент при процессе оцифровки, который идентифицирует электронный ресурс и его печатный источник посредством метаданных, размещаемых внутри самого электронного ресурса.
IAFA/WHOIS++ http://www.ifla.org/documents/libraries/cataloging/metadata/iafa.txt – шаблонно ориентированные метаданные для описания сетевых ресурсов, первоначально использовавшиеся для описания списков электронной почтовой рассылки, других ftp-архивов, а позднее распространенные на другие ресурсы. Наиболее широкое применение наблюдалось в рамках ранних проектов британской программы по электронным библиотекам eLib (ROADS и т.д.), но даже сейчас эта схема метаданных – одна из самых употребляемых.
Интероперабельность данных в системах электронной коммерции – INDECS (http://www.indecs.org) – набор метаданных, который развился из потребностей электронной коммерции в сфере шоу-бизнеса (музыка, зрелища и др.). Представляет собой наиболее сложный набор метаданных, ориентированных на управление правами на цифровой объект (вид интеллектуальной собственности, лицензионные сборы, перечисление средств правообладателям и проч.). Создается в связке с одной из наиболее известных систем идентификации цифровых объектов DOI (Digital Object Identification).
EDIFACT – одна из старейших международных систем метаданных, содержащих правила и структуру описания торгово-транспортных и других коммерческих документов. С 1998 г. поддерживается языком XML.
MATER – система метаданных, описывающая словари, классификаторы и другие лексикографические данные. Поддерживается стандартами ИСО. Имеется российская версия под названием ФОЛИЯ (Формат обмена лексикой информационных языков).
Формат Государственного регистра баз и банков данных – российский стандарт, действующий с конца 1980-х гг. и содержащий систему метаданных для баз данных и других электронных наборов данных. Утвержден Правительством РФ, поддерживается НТЦ «Информрегистр», применяется в ряде отраслей и регионов, а также в странах СНГ для ведения баз метаданных.
Кроме этих систем метаданных, обладающих развитой семантикой, применяются формальные метаданные, использование которых предусмотрено языками разметки и протоколами, принятыми в Интернете. Это HTML или HTTP метаданные – теги <meta>, определяемые соответственно спецификациями RFC 1866 и 2616.
Ввиду неудобства использования этих тегов (они не могут применяться с другими типами файлов и быстро становятся громоздкими) и с учетом массовой миграции Интернет-приложений на язык XML, был предложен так называемый RDF – шаблон описания ресурса – метод обмена метаданными на основе языка XML, разработанный Консорциумом W3 в связке с системой метаданных Дублинского ядра.
Смысл RDF заключается в том, чтобы предложить простую и универсальную модель для выражения синтаксиса метаданных. Он не обусловливает использованную семантику схемами метаданных. Для описания схемы метаданных и для обмена информацией между компьютерными системами используется XML.
Кроме перечисленных, имеются еще несколько менее известных систем метаданных, в той или иной степени претендующих на универсальность и на применение в системах ЭБ. Многие из них оформляются в виде стандартов. Следующая таблица дает сводку предложений по стандартизации метаданных.
|
Краткое название |
Полное название |
Платформа |
Кол-во стандартов |
|
1. BSR |
Basic Semantic Registry |
ISO TC 154 WG1 |
1 |
|
2. CEN/ISSS Workshop Learning Technologies |
CEN/ISSS Workshop Learning Technologies |
CEN/ISSS |
1 |
|
3. CEN TC 251 |
Health Informatics |
CEN TC 251 |
1 |
|
4. CERIF |
Common European Research Information Format |
CERIF |
1 |
|
5. Dublin Core |
Dublin Core Metadata Initiative |
Dublin Core |
2 |
|
6. GELOS |
Global Environmental Locator System Standard Element Set |
GELOS |
1 |
|
7. GILS |
Government Information Locator Service |
GILS |
1 |
|
8. IMS project |
IMS Learning Resource Metadata Information Model |
IMS Global Learning Consortium. |
1 |
|
9. ISO TC 46 SC4 |
Information and Documentation: Computer applications in information and documentation; |
ISO TC 46 SC4 |
26 |
|
10. ISO TC 46 SC9 |
Information and documentation: Presentation, identification and description of documents |
ISO TC 46 SC9 |
30 |
|
11. ISO/IEC JTC 1/SC32 |
Data management and Interchange; WG Metadata |
ISO/IEC JTC 1/SC32 |
3 |
|
12. LOM |
Learning Object Metadata |
IEEE |
1 |
|
13. MARC 21 formats |
Machine Readable Cataloguing |
MARC 21 |
11 |
|
14. MPEG-21 |
Moving Pictures Expert Group: Digital Audio-visual Framework |
MPEG |
1 |
|
15. MPEG-4 |
Moving Pictures Expert Group: Coding of audio-visual Objects |
MPEG |
1 |
|
16. MPEG-7 |
Moving Pictures Expert Group: Multimedia Content Description Interface |
MPEG |
1 |
|
17. NetCDF |
Network Common Data Form |
NetCDF |
1 |
|
18. PDS |
Planetary Data System |
PDS |
2 |
|
19. RDF |
Resource Description Framework |
W3C |
1 |
|
20. SMPTE |
Society of Motion Picture and Television Engineers |
SMPTE |
2 |
|
21. VRA |
Visual Resources Association Data Standards Committee |
VRA |
1 |
Источник: http://www.schemas-forum.org/stds-framework/1.html
Общая схема взаимосвязи различных систем метаданных и разрабатываемых на их основе стандартов приведена на рисунке:
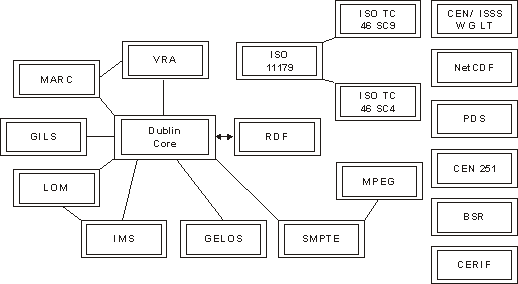
Сопоставительный
анализ Дублинского ядра
и других систем метаданных
В качестве базового средства формирования метаданных для описания широкого класса цифровых объектов обычно упоминается Дублинское ядро метаданных. Так, при опросе специалистов различных стран, присутствовавших в декабре 2000 г. в Лондоне на очередной выставке Online Information, в качестве перспективного стандарта метаданных для описания электронных ресурсов представители США, Англии, Франции, Германии, Японии, не сговариваясь, называли именно Дублинское ядро. Известно, что некоторые национальные системы уже объявили о принятии Дублинского ядра в качестве национального стандарта (Австралия, Швеция).
Основные черты Дублинского ядра. С 1995 г. международная группа под руководством Stuart Weibel из OCLC работает над созданием простого набора элементов метаданных, которые могли бы применяться для широкого набора библиотечных материалов. Набор таких элементов, созданный группой, известен как Дублинское ядро (по названию г. Дублин в штате Огайо, где расположена штаб-квартира OCLC и где состоялась первая рабочая встреча). Несколько сотен людей участвовали в рабочих встречах Дублинского ядра или в обсуждениях посредством электронной почты. Присущий им дух сотрудничества является примером того, как индивидуумы с различными интересами могут работать вместе.
Следующие пятнадцать элементов составляют набор метаданных Дублинского ядра. Все элементы являются необязательными и могут повторяться.
Title (Заголовок) – название, присвоенное ресурсу создателем или издателем.
Creator (Автор) – человек или организация, изначально ответственная за интеллектуальное содержание ресурса (в случае рукописного документа – авторы; в случае визуальных ресурсов – исполнители, фотографы или иллюстраторы).
Subject (Предмет) – тема ресурса. Обычно предмет выражается в ключевых словах или фразе, описывающей предмет или содержание ресурса. Приветствуется использование контролируемых словарей и формальных схем классификации.
Description (Описание) – текстовое описание содержания ресурса (включая реферат в случае документов или описание содержания в случае визуального ресурса).
Publisher (Издатель) – организация, ответственная за создание ресурса в его нынешней форме (например, издательский дом, университетский департамент или корпорация).
Contributor (Участник создания материала) – человек или организация, которые не являются авторами (не обозначены в элементе автор), но внесли значительный интеллектуальный вклад в ресурс, причем этот вклад вторичен по отношению к любому человеку или организации, указанной в числе авторов (например, редактор, переводчик, иллюстратор).
Date (Дата) – дата, указывающая на создание или появление (в доступном виде) ресурса.
Type (Тип) – категория ресурса (домашняя страничка, роман, поэма, статья, препринт, технический отчет, эссе, словарь и т.п.).
Format (Формат) – формат представления данных ресурса (обычно указывается тип программного обеспечения и, возможно, тип компьютера, которые могут быть необходимы для отображения и работы с ресурсом).
Identifier (Идентификатор) – набор букв или цифр, который обычно используется для уникальной идентификации ресурса. (В случае сетевых ресурсов примерами являются URL и URN.)
Source (Источник) – информация о вторичном источнике, из которого был получен настоящий ресурс.
Language (Язык) – язык, на котором изложено интеллектуальное содержание ресурса.
Relation (Связь) – идентификатор вторичного ресурса и его связь с настоящим ресурсом. Этот элемент позволяет связывать между собой близкие ресурсы, а также описания ресурса, которые необходимо показать. (Примеры – издание книги и глава книги.)
Coverage (Охват) – характеристики местонахождения и временной продолжительности ресурса.
Rights (Права) – утверждение об авторских правах и управление ими; идентификатор, связанный с таким утверждением; идентификатор, связанный с сервисом, представляющим информацию об управлении правами на данный ресурс.
Как указывается в RFC2413, элементы Дублинского ядра можно условно разбить на три группы:
Content – элементы, в основном относящиеся содержанию ресурса – Title, Subject, Description, Type, Source, Relation, Coverage.
Intellectual Property – элементы, в основном рассматриваемые с позиции интеллектуальной собственности, – Creator, Publisher, Contributor, Rights.
Instantiation – элементы, в основном относящиеся к данному экземпляру ресурса, – Date, Format, Identifier, Language.
Основное преимущество Дублинского ядра заключается в том, что использовать его весьма просто по сравнению с традиционными методами каталогизирования, применение которых требует профессиональной подготовки. Однако простота конфликтует с точностью. Команда много работала над этим парадоксом. Первоначальная цель заключалась в создании простого набора элементов метаданных для неподготовленных людей, которые публикуют электронные материалы с описанием своих результатов. Некоторые продолжают придерживаться этого минималистского подхода; они хотели бы видеть простой набор правил, которыми мог бы воспользоваться любой. Другие предпочитают ориентироваться на преимущества более тщательно разработанных правил каталогизирования и согласны на увеличение трудоемкости и стоимости. Они указывают на то, что дополнительные структурные элементы позволяют добиться большей точности в метаданных. Например, если поле предмет заполнялось с использованием классификатора Дьюи, было бы полезно отразить этот факт в метаданных. Для дальнейшего повышения эффективности метаданных при обработке информации предлагается присваивать некоторым элементам некоторые «значения». Это может быть определенный набор, список типов, которым могут руководствоваться составители описаний.
Таким образом, можно сказать, что стратегию Дублинского ядра развивают «минималисты», с одной стороны, и «структуралисты», с другой. Первые исходят из первоначального намерения создать систему, полезную для людей без специальной подготовки. Вторые хотят создать систему более сложную, требующую исчерпывающего описания и подготовленных сотрудников.
Пятнадцати элементов явно недостаточно для информационных систем типа электронных библиотек. Чтобы сохранить совместимость с простейшим описанием из 15 элементов и в то же время увеличить детализацию и сложность описаний различные организации, в том числе и рабочие группы самой Инициативы Дублинского ядра (DCMI), разрабатывают расширения, дополнительные квалификаторы для базовых элементов. Длительное время в этом вопросе наблюдались определенный произвол и неопределенность, однако летом 2000 г. появились рекомендации DCMI, описывающие набор квалификаторов.
Ряд специалистов считает, что Дублинское ядро, разработанное в результате выделения минимального ядра на основе компромисса, имеет ряд существенных недостатков. Среди них Г. Руст (http://www.dlib.org/dlib/july98/rust/07rust.html) отмечает следующие:
-
отсутствуют описания таких понятий, как продолжительность, размер или число компонентов;
-
отсутствуют связи между местоположением и событиями (датами);
-
недостаточна гибкость для описания времени (нет диапазонов протяженности, возможности работы с минутами и секундами);
-
произвольно отделены Creators и Contributors (а также, что менее важно, Titles and Identifiers), отсутствуют условия для определения их роли или статуса;
-
Description рассматривается как аннотация, описательный элемент вместо логически отдельной единицы с собственными признаками и правами;
-
Publisher трактуется как описательный, а не правовой элемент;
-
элементы Source и Relation неадекватно описывают отношения создания;
-
определениям недостает точности.
Статья Г. Руста характерна как пример претензий к Дублинскому ядру со стороны отраслей, для представления которых его возможностей недостаточно (однако следует иметь в виду, что минимальный набор элементов в принципе не предназначен для описания тонких вопросов специфического сектора). Тем не менее представляется полезным проследить аргументацию автора. Далее он пишет, что имеются существенные вопросы по большинству из пятнадцати элементов.
Во-первых, их группировка в три категории (Content, Intellectual Property и Instantiation) реально не помогает. Почему, например, Title относится к Content, а Identifier – к Instantiation? Одно произведение может иметь различные названия в различных контекстах. На каждой стадии Dublin Core оставляет возможности для большого числа исключений из правил.
Во-вторых, признаки, терминология и примеры взяты преимущественно из текстовых произведений. Это в значительной степени не соответствует интересам владельцев и издателей звуковых, аудиовизуальных и абстрактных работ, несмотря на наличие перекрестных словарей.
В-третьих, структура Дублинского ядра не является ни достаточно жесткой, чтобы удовлетворить требования системы, основанной на правах (которые нуждаются в фиксированной структуре), ни настолько свободной, чтобы согласовать структуру, взятую из другого источника. Принципы заимствования стандартных наборов значений (особенно Canberra Qualifiers) признаются, но не применяются достаточно жестко.
Наконец – и это главная трудность применения Дублинского ядра для правообладателей – метаданные права рассматриваются там как дополнительный, 15-й элемент (Rights), а фактически это понятие охватывает 13 из других 14 элементов. При последовательном и корректном понимании вопросов, связанных с правами и описывающими метаданными, следовало бы передать половину Дублинского ядра либо полностью игнорировать эти понятия.
Все это может привести к тому, что владельцы прав создадут собственный набор, удовлетворяющий их потребностям. Однако в сетевой структуре бессмысленно иметь один набор метаданных для исследований, а другой – для управления правами: по сути это одно и то же. Если Дублинское ядро станет стандартом, то что оно будет стандартизовать? Ядро метаданных? Если необходим формальный стандарт, аргументация этого документа предполагает, чтобы при этом учитывались и правовые, и описательные потребности. В таком случае предназначено ли Дублинское ядро только для описания ядра метаданных в целях поиска, если оно почти полностью пересекается с требованием для управления правами?
Разработчики Дублинского ярда утверждают, что внедрение единой системы метаданных на этой основе побудило бы авторов и издателей сопровождать свои данные ими же разработанными метаданными. Это позволило бы разработчикам средств для сетевых публикаций включать шаблоны для этой информации непосредственно в программное обеспечение, облегчая поставщикам информации их разработку. Метаданные, созданные информационными провайдерами, должны служить базой для более детальной каталогизации или описаний в конкретных предметных областях. Вдобавок это обеспечило бы общий для всех приложений базовый набор элементов, даже если определенным профессиональным группам потребовалась бы более специфическая информация. В то время как имеющиеся поисковые машины не в состоянии обеспечить релевантные результаты поиска при просмотре огромного количества ресурсов Интернета, поиск с использованием метаданных мог бы дать гораздо более точные результаты.
Дублинское ядро – решение, рожденное методами доцифровой эпохи. Его распространение на среду, где права и описания глубоко взаимозависимы, может быть очень дорогостоящим. Мы не просто получим новый круг конкурирующих версий, как это было при развитии AACR, MARC и других «стандартов» (возможно, это уже началось и с Дублинским ядром), нам придется просить владельцев прав (которые сейчас вряд ли в состоянии внедрить и один чистый набор метаданных) создать по крайней мере два: один – для управления правами, другой – для поиска; к тому же мы создадим огромные неудобства для разработчиков, которым придется иметь дело с двумя частично несовместимыми «стандартами» метаданных.
По-видимому, универсальность Дублинского ядра не всеобъемлюща, и для отдельных предметных областей надолго сохранится потребность в локальных стандартах, учитывающих специфику отрасли – при использовании схожих подходов и принципов.
В настоящее время проект INDECS формально закрыт, но работы в этом направлении не прекращаются. Его участники основали некоммерческую организацию Indecs Framework Ltd, продолжается сотрудничество с International DOI Foundation (IDF). В любом случае этот проект является наиболее продвинутым в направлении систем метаданных, ориентированных на управление правами на цифровые объекты. В связи с этим ведутся исследования по сопоставлению системы метаданных INDECS с другими системами метаданных.
Особый интерес представляет для нас система метаданных, используемая в GILS. Дело в том, что идеология этой системы практически тождественна принципам функционирования Государственного регистра баз и банков данных, который по замыслу должен стать ядром навигационной системы всех государственных информационных ресурсов России. Цель GILS – обеспечить гражданам поиск всех информационных ресурсов, созданных за средства налогоплательщиков – на любых носителях и языках. Выбранная стратегия наследует международные стандарты информационного поиска, в частности стандарт ISO 23950, эквивалентный американскому стандарту ANSI/NISO Z39.50 (в 1997 г. ISO 23950 заменил ISO 10162 и ISO 10163). Z39.50 первоначально разработан для использования в библиотечной среде и информационных службах, а к настоящему времени получил широкое применение в глобальных сетях.
В рамках GILS требуется описывать не только книги и наборы данных, но также людей, события, собрания, артефакты и т.д. Что касается сетевой информации, GILS поддерживает гиперссылки для доступа к взаимосвязанным ресурсам.
О соотношении GILS и Дублинского ядра. 15 элементов Дублинского ядра отображаются на систему метаданных GILS с помощью специальных средств (см. http://www.loc.gov/marc/dccross.html). В Дублинском ядре нет фиксированных правил синтаксиса (хотя существует соглашение W3C о том, как записывать элементы Дублинского ядра на HTML). В этом Дублинское ядро и GILS сходны. В отличие от GILS Дублинское ядро не определяет поисковые средства. GILS–согласованный поиск может успешно работать в сочетании с семантикой Дублинского ядра.
О соотношении GILS и MARC. GILS наследует семантику MARC для элементов, используемых для поиска. Взаимно однозначное соответствие между элементами GILS и MARC описано в GILS Profile (см. http://www.gils.net/prof_v2.html#annex_b ).
GILS создается с целью интеграции библиотечных и сетевых ресурсов на основе сочетания библиотечной практики библиографических описаний с сетевыми и компьютерными технологиями. Поскольку GILS является важной составной частью Национальной информационной инфраструктуры, его идеологи ставят широкомасштабные цели реализации права на информацию в рамках создания глобального информационного сообщества.
Другие системы метаданных, упомянутые выше, не претендуют на универсальное применение и поэтому не подвергаются столь строгому критическому анализу. Тем не менее сравнительный анализ систем метаданных, особенно семантический, является объектом многих исследований. Стали даже говорить о специальном направлении исследований, получившем название картографирование метаданных.
Проблемы создания метаданных
Кто создает метаданные? До тех пор, пока библиотеки как учреждения и библиотекари как профессионалы в своей области являлись основными производителями метаданных для карточных и электронных каталогов и индексаторами библиографических баз данных, необходимости в обсуждении этого вопроса не было. Однако в настоящее время теоретически каждый может создать метаданные для любого цифрового объекта в соответствии со своими потребностями и разместить их в сетевой среде, установив ссылку на сам объект. В идеале создатель или разработчик цифрового объекта обладает самым глубоким знанием о нем (содержание, назначение, отношение к другим документам и т.д.). Так, на различных сайтах имеются специальные шаблоны для описания метаданных, которые запрашиваются у автора (иногда в обязательном порядке). Эти метаданные могут автоматически размещаться их в HTML – заголовках документа или загружаться в базы данных.
Примерами этому могут служить шаблоны Nordic Metadata (http://www.ub.lu.se/metadata/DC-creator.html), форма для предоставления метаданных в рамках проекта «Немецкие диссертации онлайн» (German Dissertations Online Project) и форма для регистрации документов (электронных или неэлектронных) в хранилище метаданных по образовательным материалам и учебным курсам (http://dbs.schule.de/db/listen/html) на сервере образовательных ресурсов Германии (http://dbs.schule.de/).
В других случаях применяются специально разработанные механизмы автоматического поиска информации, которые способны с высокой степенью точности извлечь из HTML-файлов или форматированного текста имя автора, названия связанных с ним организаций, дату или другие параметры и разместить эти данные в индексе или создать набор метаданных для данного документа. Подобная технология применяется в настоящее время на серверах препринтов и архивов, таких, как Математический сервер препринтов в Германии (Osnabruck – проект программы eLib http://elib.uni-osnabruck.de/talks/dfg/kurzELib.html) и ряд других. Несмотря на то, что точность извлечения метаданных в отдельной области путем анализа текста до сих пор остается под вопросом, методы кластеринга слов и другие методы анализа текста продолжают совершенствоваться и относятся к сфере исследований в области электронных библиотек, которые повлияют на развитие метаданных в целом и их значимость в будущем.
В случае, если соответствующие метаданные не предоставляются автором или создателем лично, издатель вынужден нанимать специалистов для их создания. Это могут быть библиотекари или другие информационные специалисты, ученые в данной области или компании, нанятые для этой цели. Составление метаданных является достаточно квалифицированным трудом и требует значительных затрат. Метаданные могут быть добавлены непосредственно в документ, размещены в хранилище метаданных, используемом для информационного поиска или храниться в отдельном файле. Таким образом, в одной сети могут теоретически находиться различные наборы и формы представления метаданных для одного и того же документа.
В РГБ реализуется проект «Создание систематического каталога российских ресурсов Интернет», в рамках которого создателям ресурсов предлагается механизм получения стандартного описания их собственного ресурса, которое должно храниться в самом ресурсе. Создателю ресурса остается только поддерживать в актуальном состоянии это описание. При наличии такого описания возможно создание программы-робота, которая без участия человека будет просматривать весь Интернет или его часть, находить новые или измененные ресурсы, выбирать из ресурсов описания, подготовленные создателями, и размещать их в создаваемом каталоге. Таким образом, будет обеспечена актуальность каталога, а его полнота будет зависеть от создателей ресурсов.
В рамках этого же проекта создан пакет прикладных программ для ведения систематического каталога ресурсов Интернет. Вопрос о формате описания решен в пользу формата Дублинского ядра.
Возможно, авторы проекта излишне оптимистично оценивают готовность владельцев ресурсов вводить необходимый комплект метаданных.
При описании электронных ресурсов, в частности при создании каталогов и справочников о ресурсах Интернета, многие авторы пользуются собственными рубрикаторами и формами для описания (метаданными). Наиболее популярный в мире каталог ресурсов Yahoo! использует собственный классификатор веб-ресурсов.
Новый проект поисковой системы Яndex, направленный на повышение релевантности при поиске Интернет-ресурсов, фактически основан на оригинальном наборе метаданных. Он, в частности, содержит такие характеристики ресурса, как источник информации, жанр, ряд других признаков, с помощью которых можно уточнять поисковый контекст и значительно уменьшать пространство для поиска. В конечном счете такой подход приводит к сокращению времени поиска и повышению его качества.
В обозримой перспективе останется необходимость в ручной (в дополнение к автоматизированной) каталогизации информационных ресурсов Интернета.
Заключение
Системы метаданных являются одним из важнейших компонентов электронных библиотек, который в значительной степени определяет функциональные возможности ЭБ и, шире, универсальных систем информационного поиска. В связи с этим понятно внимание зарубежных разработчиков к этой проблеме. Поскольку Интернет – основная среда реализации ЭБ, весьма важным и определяющим является учет требований сетевой среды в проектных решениях в области метаданных. Основной вариант в настоящее время составляют решения, основанные на использовании языка XML и протокола HTTP. В то же время при активной поддержке правительства США, а теперь и правительств других стран, развивается система метаданных GILS, основанная на протоколе Z39.50, который многие специалисты считают неперспективным.
Если говорить о семантике метаданных, то по популярности как среди российских, так и среди зарубежных исследователей с большим отрывом лидирует проект универсальной системы метаданных Дублинского ядра. Однако следует отметить, что в пределах определенных категорий цифровых объектов, таких, как геопространственные системы, книжная торговля или музейные ресурсы, тематически ориентированные метаданные распространены гораздо больше, чем универсальные. Кроме того, проект Дублинского ядра подвергается критике с точки зрения его возможностей для проблемы управления правами доступа к цифровым объектам.
В России, к большому сожалению, отсутствуют систематические исследования и разработки в области метаданных. Исключением и наиболее продвинутой является система библиографических метаданных, основанная на формате MARC, создаваемая при активной поддержке Минкультуры РФ. Внедрение этой системы практически охватывает большинство библиотечных автоматизированных систем, доступных через Интернет. Действующая в настоящее время программа РФФИ по электронным библиотекам сформирована таким образом, что общесистемные исследования, к которым относится и разработка системы метаданных, не востребованы.
В других сферах достижения в области метаданных более скромны: в электронной коммерции начинают применяться Интернет-приложения системы EDIFACT, а в ГИС-сообществе делаются попытки внедрить стандарт на метаданные для геопространственных данных, основанные на стандарте DIF. Кроме того, функционирует и постепенно распространяется система метаданных Государственного регистра баз и банков данных. Создаются системы метаданных и для различных конкретных систем, например для Государственного регистра населения или Федерального земельного кадастра. Однако все эти проекты разрознены и не образуют более или менее единого подхода к проблеме метаданных. Можно надеяться, что этот пробел будет устранен при реализации межведомственной программы «Электронные библиотеки России», идеология которой направлена именно на общесистемные разработки и обеспечение совместимости информационных ресурсов России.
Copyright © 1995-2002 ГПНТБ России